
Pandas是一個非常強大的數據分析方面的Python package. 如果是做Machine Learning或者數據分析, 掌握Pandas很省去很多麻煩. 許多Machine Learning前期的數據處理也是用Pandas做得.
IBKR(Interactive Brokers, 有時簡稱IB, 中文叫盈透證券)是美國老牌券商, 也是我的主要使用的券商. 又到了辭舊迎新的時候, 需要看看2020投資收益, 於是趁新年長周末寫點小程序做點數據分析. 而這正好覆蓋了Pandas的各種常用functions.
下載IB Statement
IB Statement提供多種方式下載, 比如html, pdf, csv. 用作數據處理選csv. 內容大概長這樣
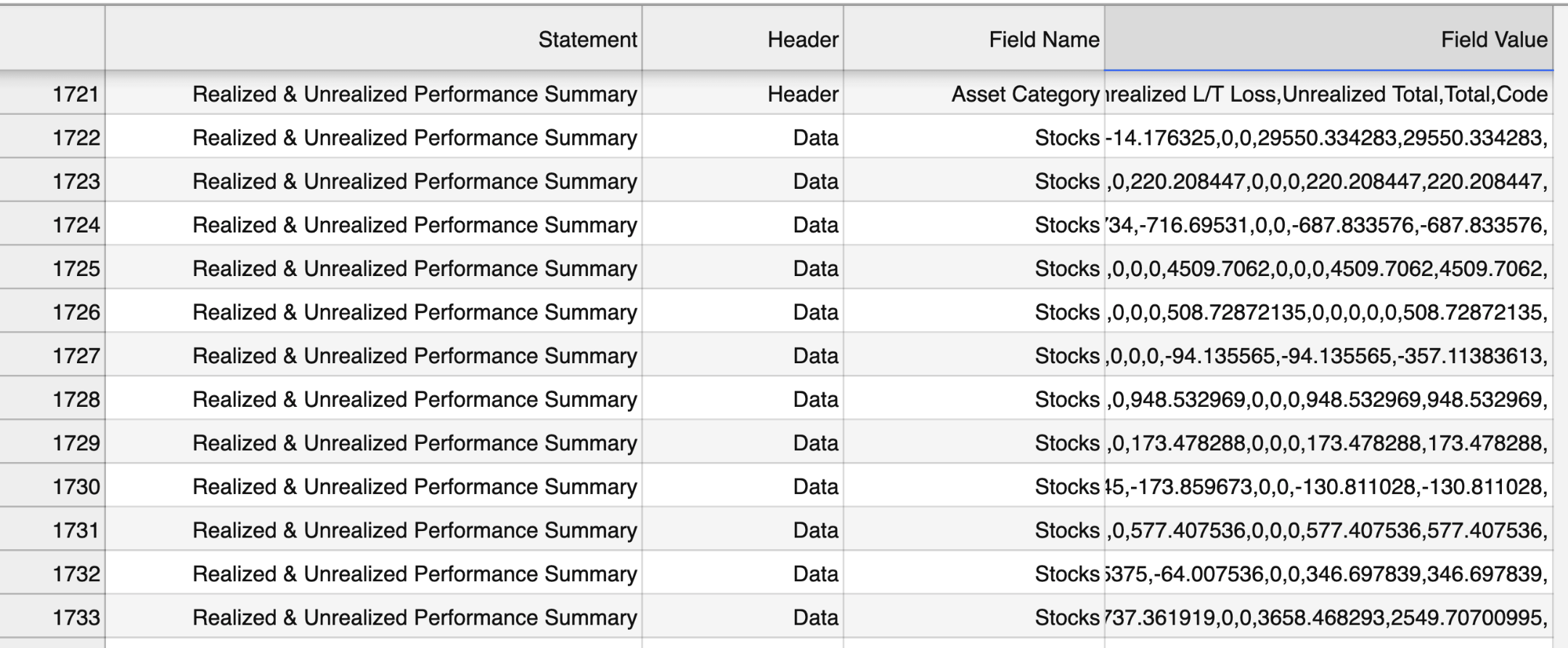
Statement這個column是內容, 裡面有很多項, 而這裡我只看「Realized & Unrealized Performance Summary”, 然後相同的第一列後面的列數都是一樣的. 上圖是Jupyter Lab的顯示有問題. 因為文件其實可以看成很多CSV files連在一起, 而第一列可以看成是小csv的文件名. 然後第二列是Header或者Data. Header那行就是告訴你後面的Data行里每一列都是什麼. 於是我們可以把數據讀到內存里.
建立Pandas DataFrame
import pandas as pd
field = 'Realized & Unrealized Performance Summary'
f = open('statement.csv', 'r')
rows = []
for line in f:
cols = line.strip().split(',')
if cols[0] == field:
if cols[1] == 'Header':
header_row = cols[2:]
else:
rows.append(cols[2:])
header_ros是個list of string
['Asset Category', 'Symbol', 'Cost Adj.', 'Realized S/T Profit', 'Realized S/T Loss', 'Realized L/T Profit', 'Realized L/T Loss', 'Realized Total', 'Unrealized S/T Profit', 'Unrealized S/T Loss', 'Unrealized L/T Profit', 'Unrealized L/T Loss', 'Unrealized Total', 'Total', 'Code']
而rows是list of list. 就是list of rows
[['Stocks', 'AAPL', '0', '0', '0', '0', '0', '0', '29564.510608', '-14.176325', '0', '0', '29550.334283', '29550.334283', '\n'], ['Stocks', 'AMD', '0', '0', '0', '0', '0', '0', '220.208447', '0', '0', '0', '220.208447', '220.208447', '\n'], ... ]
接下來就可以用Panda create dataframe了
df = pd.DataFrame(rows, columns = header_row) df.head(5)

這裡有個問題. Created出來的dataframe的數據類型有數字有string, 全部都是object. 如果sort by數字column得到的結果是sort by string, 並不是我們想要的. 可以用dtypes來確定
df.dtypes
Asset Category object Symbol object Cost Adj. object Realized S/T Profit object Realized S/T Loss object Realized L/T Profit object Realized L/T Loss object Realized Total object Unrealized S/T Profit object Unrealized S/T Loss object Unrealized L/T Profit object Unrealized L/T Loss object Unrealized Total object Total object Code object dtype: object
這裡我把需要轉換成數字的columns轉換了
header_text_col = set(['Asset Category', 'Symbol', 'Code']) num_col = list(set(header_row) - header_text_col) df[num_col] = df[num_col].apply(pd.to_numeric) df.dtypes
Asset Category object Symbol object Cost Adj. int64 Realized S/T Profit float64 Realized S/T Loss float64 Realized L/T Profit int64 Realized L/T Loss float64 Realized Total float64 Unrealized S/T Profit float64 Unrealized S/T Loss float64 Unrealized L/T Profit int64 Unrealized L/T Loss float64 Unrealized Total float64 Total float64 Code object dtype: object
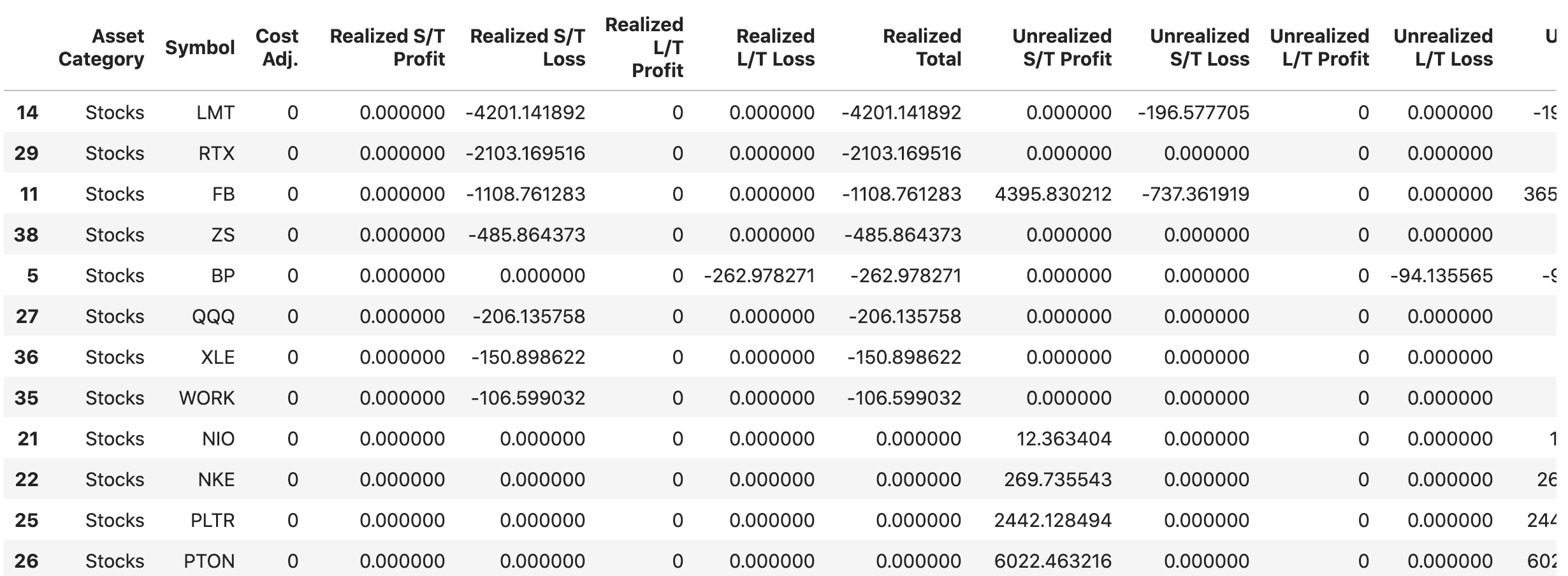
這樣就可以對數字類型的column進行排序了, 比如下面指令做2步操作
1. 選出Asset Category是”Stocks”的rows, 相當於SQL里的where, 語法為df[df['Asset Category'] == 'Stock'], return是另一個filtered好的dataframe
2. 按Realized Total從小到大排序, return也是另一排序好的dataframe
df[df['Asset Category'] == 'Stock'].sort_values(by=['Realized Total'], ascending=True)
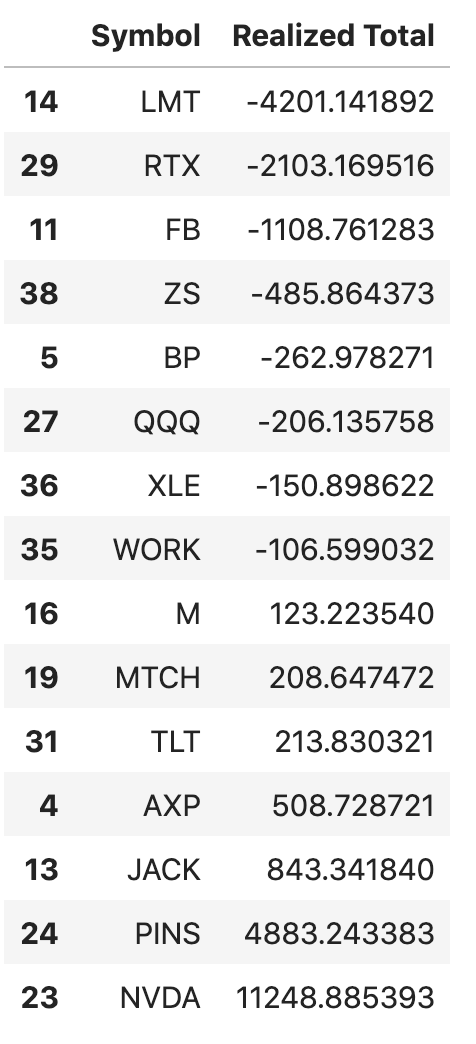
還可以畫圖
stock_gain = df[
(df['Asset Category'] == 'Stocks') & (
df['Realized Total'] != 0.0)][['Symbol', 'Realized Total']].sort_values(
by=['Realized Total'], ascending=True)
stock_gain
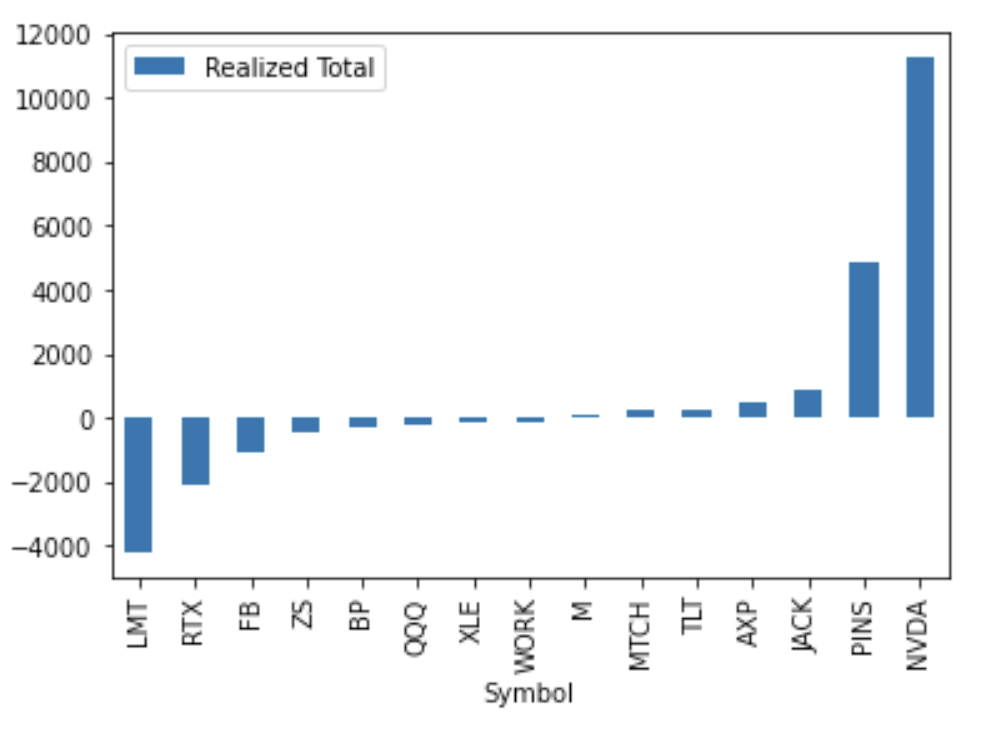
還可以畫圖
stock_gain.plot.bar(x='Symbol')
技術小結
建立dataframe
rows是list of rows(lists), header_row是list of string
df = pd.DataFrame(rows, columns = header_row)
顯示前n行
df.head(10)
顯示後面n行
df.tail(10)
把特定columns轉換成數字(numerical type)
num_col是list of strings, 下面命令會把num_col里的columns都轉化成數字類. 類似SQL里的select cast(col1 as double), cast(col2 as double), ... from df
df[num_col] = df[num_col].apply(pd.to_numeric)
Filter和sort
類似SQL里, select * from df where asset_category = 'Stocks' order by realized_total asc;
df[df['Asset Category'] == 'Stocks'].sort_values(by=['Realized Total'], ascending=True)
